Your game has data – sprites, sound effects, music, text – and you need to store it somehow. Sometimes you can encapsulate everything into a single SWF, .unity3d or EXE file, but in some cases that won’t be suitable. In this technical tutorial, we’ll look at using custom binary files for this purpose.
Note: This tutorial assumes you have a basic understanding of bits and bytes. Check out An Introduction to Binary, Hexadecimal, and More and Understanding Bitwise Operators on Activetuts+ if you need to revise!
Pros and Cons of Custom Binary Files
There are a few pros and cons to using custom binary file formats.
Creating something like a resource container (as this tutorial will do) will reduce disk/server thrashing and will typically make resource loading a lot easier because multiple files will not need to be loaded. Custom file formats can also add an extra layer of security in the form of obfuscation to game resources.
On the flip side you will need to actually generate the custom files one way or another before you can use them in a game, but that is not as difficult as it might sound — especially if you or someone you know can create something like a JAR file that can be dropped into a build process with relative ease.
Understanding Primitive Data Types
Before you can begin to design your own binary file formats you will need an understanding of the primitive data types (building blocks) that are available to you. The number of primitive data types is actually limitless but there is a common set that most programmers are familiar with and use, and these data types typically represent multiples of 8 bits.
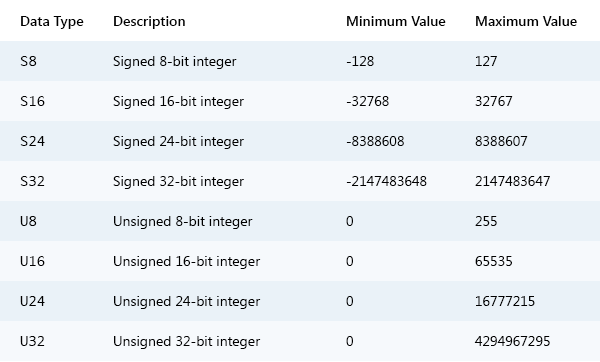
As you can see, these primitive data types provide a wide range of integer values and you will find them at the core of most binary file specifications. There are a few more primitive data types, such as floating point numbers, but the integer data types listed above are more than adequate for this introduction and for most binary file formats.
Understanding Structured Data Types
Structured data types (or complex data types) represent specific elements (chunks) of a binary file, and they consist of primitive data types or other structured data types.
You can think of structured data types as objects or class instances in a programming language, with each object declaring a set of properties. Structured data types can be visualised using simple object notation.
Here is an example of a fictitious file header:
HEADER
{
signature U24
version U8
length U32
}
So here the structured data type is named HEADER and it has three properties labeled signature, version and length. Each property in this example is declared as a primitive data type but properties can also be declared as structured data types.
If you are a programmer you are probably beginning to realise how easy it would be to represent a binary file in an OOP based programming language; let’s take a quick look at how this HEADER data type could be represented in Java:
class Header
{
public int signature; // U24
public int version; // U8
public long length; // U32
}
Designing a Custom Binary File
At this point you should be familiar with the basics of binary file structures, so now is the time to take a look at the process of designing a working custom file format. This file format will be designed to hold a collection of game resources including images and sounds.
The Header
The first thing that should be designed is a data structure for the file header so the file can be identified before the remainder of the file is loaded into memory. Ideally the file header should at least contain a signature field and a version field:
HEADER
{
signature U24
version U8
}
The file signature you choose to use is up to you: it can be any number of bytes, but most file formats have a human-readable signature containing three or four ASCII characters. For my purposes, the signature field will hold the character codes of three ASCII characters (one byte per character) and will represent the string “RES” (short for “RESOURCE”), so the byte values will be 0x52, 0x45 and 0x53.
The version field will initially be 0x01 because this is Version 1 of the file format.
The resource file itself is actually a structured data type which contains a header and will later contain other elements. It currently looks like this:
FILE
{
header HEADER
}
Images
The next thing will we take a look at is the data structure for images.
The resource file will store an array of ARGB colour values (one per pixel) and allow that data to be optionally compressed using the ZLIB algorithm. The image dimensions will also need to be included in the file along with an identifier for the image (so the image can be accessed after it has been loaded into memory):
IMAGE
{
id STRING
width U16
height U16
compressed U8
dataLength U32
data U8[dataLength]
}
There are a couple of things in that structure that need your attention; the first is the U8[dataLength] part of the structure and the second is the STRING data structure used for the id, which was not defined in the table of data types above.
The former is basic array notation — it simply means that dataLength number of U8 values need to be read from the file. The data field contains the image pixels, and the compressed field indicates whether the the data field is compressed. If the compressed value is 0x01 then the data field is ZLIB compressed, otherwise the file decoder can assume the data field is not compressed. The benefit of using ZLIB compression here is the IMAGE file structure will end up being a similar size to a PNG encoded version of the image.
The STRING data structure is as follows:
STRING
{
dataLength U16
data U8[dataLength]
}
For this file format all strings will be encoded as UTF-8 and the bytes of the encoded string will be located in the data field of the STRING data structure. The dataLength field indicates the number of bytes in the data field.
The resource file structure now looks like this:
FILE
{
header HEADER
imageCount U16
imageList IMAGE[imageCount]
}
As you can see the file now contains a header, a new imageCount field that indicates the number of images in the file, and a new imageList field for the images. This in itself would be a useful file format to store multiple images, but it would be even more useful if it held multiple resource types, so will will now take a look at adding sounds to the file.
Sounds
Sounds will be stored in the file in a similar way to images, but instead of storing raw pixel colour values the file will store raw sound samples in varying bit resolutions:
SOUND
{
id STRING
dataFormat U8
dataLength U32
// 8-bit samples
if( dataFormat == 0x00 )
{
data U8[dataLength]
}
// 16-bit samples
if( dataFormat == 0x01 )
{
data U16[dataLength]
}
// 32-bit samples
if( dataFormat == 0x02 )
{
data U32[dataLength]
}
}
Oh my goodness, conditional statements! Because the dataFormat field indicates the bit rate of the sound, the format of the data field needs to be variable, and that is where the simple and programmer friendly conditional statement syntax comes into play.
Looking at the data structure you can easily see which format the data field values (sound samples) will be using, given a specific dataFormat value. When adding fields like dataFormat to a data structure the values those fields can contain is entirely up to you. The values 0x01, 0x02 and 0x03 are being used in this example simply because they are the first unused values available in the byte.
The resource file structure now looks like this:
FILE
{
header HEADER
imageCount U16
imageList IMAGE[imageCount]
soundCount U16
soundList SOUND[soundCount]
}
Generic Data
The last thing that will added to this resource file structure is generic data; this will allow miscellaneous game related data (in various formats) to be packed into the file.
Like the IMAGE data structure this new DATA structure will support optional ZLIB compression because text-based data such as JSON and XML generally benefit from compression, and this will also obfuscate the data within the file:
DATA
{
id STRING
compressed U8
dataFormat U8
dataLength U32
data U8[dataLength]
}
The compressed field indicates whether the data field is compressed: a value of 0x01 means the data field is ZLIB compressed.
The dataFormat indicates the format of the data, and the values this field can contain is up to you. You could for example use 0x00 for raw text, 0x01 for XML and 0x02 for JSON. A single unsigned byte (U8) can hold 256 different values and that should be more than enough for all of the various data formats that you might want to use in a game.
The final resource file structure looks like this:
FILE
{
header HEADER
imageCount U16
imageList IMAGE[imageCount]
soundCount U16
soundList SOUND[soundCount]
dataCount U16
dataList DATA[dataCount]
}
As far as file formats go this one is relatively simple — but it’s functional and it demonstrates how file formats can be represented and structured in a sensible and understandable way.
Understanding Byte Orders
There is one more important thing that you may need to know about binary files: multibyte values stored in binary files can use one of two byte orders (this is also known as the “endian”). The byte order can either be LSB (Least Significant Byte first, or “little-endian”) or MSB (Most Significant Byte first, or “big-endian”). The difference between the two byte orders is simply the order in which the bytes are stored.
For example, a 24-bit RGB colour value consists of three bytes, one byte for each colour channel. The byte order of a file determines whether those bytes are stored in the file as RGB (big-endian) or BGR (little-endian).
A lot of modern programming languages provide an API that will allow you to toggle the byte order while you are reading a file into memory, so the reading of multibyte values from a binary file is not something programmers usually need to be concerned about. However, if you are reading a file byte-by-byte then you will need to be aware of the file’s byte order.
The following Java code demonstrates how to read a 24-bit value (in this case a RGB colour) from a file while considering the file’s byte order:
bigEndian boolean = true;
int readU24( InputStream input ) throws IOException
{
int value = 0;
if( bigEndian )
{
value |= input.read() << 16; // red
value |= input.read() << 8; // green
value |= input.read() << 0; // blue
}
else // little endian
{
value |= input.read() << 0; // blue
value |= input.read() << 8; // green
value |= input.read() << 16; // red
}
return value;
}
The actual reading and writing of binary files is beyond the scope of this tutorial, but in that example you should be able to see how the order of the three bytes of a 24-bit value is flipped depending on the byte order (endian) of a file. Are there any benefits of using one byte order instead of the other? Well, not really — byte orders are only of concern for hardware not software.
Where you go from here is up to you, but I hope this tutorial has made custom file formats a little less scary to consider using in your own games!